
Research
 Research
Research
My research is focused on three aspects: (i) Constructing challenging & realistic benchmarks, focusing on evaluation and benchmarking (ii) Building efficient retrieval systems, whose quality and cost can be optimized and generalize to challenging domains, and (iii) Standardizing RAG evaluation, building a better foundation within the IR & NLP community.
To answer these questions, my research develops new benchmarks such as BEIR or MIRACL to enable realistic evaluations, and constructs efficient models with GPL & SWIM-IR. This accelerates RAG systems to help craft language model answers with reduced hallucinations and improved accuracy seen across domains and languages.
 Data Efficiency: Transfer Learning, Data Augmentation, and Zero-shot Learning
Data Efficiency: Transfer Learning, Data Augmentation, and Zero-shot Learning
In order to train neural retriever systems, large amounts of human-labeled training data are required, which is often cumbersome and expensive to generate for real-world tasks. Data efficiency plays a crucial role in addressing this challenge. Transfer learning is motivated by distilling knowledge from pretrained models or LLMs to train data-efficient models. Data augmentation techniques involve generating high-quality synthetic data for training purposes. Zero-shot learning enables models to generalize to unseen classes or queries without any training examples.
 Languages: Multilingual Retrieval
Languages: Multilingual Retrieval
Multilingual retrieval aims to provide relevant search results for users searching across multiple languages. Multilingual retrieval involves various challenges, including language mismatch, translation ambiguity, and language-specific resource limitations. To overcome these challenges, machine translation, cross-lingual IR, and multilingual embeddings have been employed. However, training data for such tasks is even scarcer than English, making it an important challenge.
 Publications
Publications
For an updated list of publications, please refer either to my Google Scholar profile or Semantic Scholar profile.
* denotes equal contribution
2024

|
Resources for Brewing BEIR: Reproducible Reference Models and Statistical AnalysesEhsan Kamalloo, Nandan Thakur , Carlos Lassance, Xueguang Ma, Jheng-Hong Yang, Jimmy Lin.To appear in SIGIR 2024 (Resource Track), 2024. University of Waterloo, Naver Labs Resources to support the BEIR benchmark: Reproducible lexical, sparse and dense baselines and statistical analyses. |
|
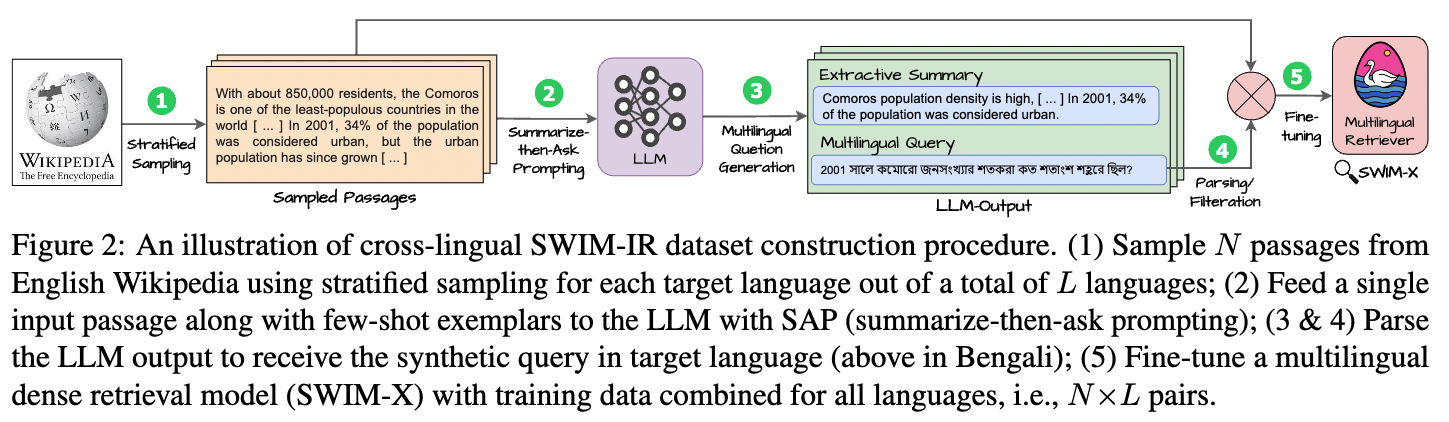
Leveraging LLMs for Synthesizing Training Data Across Many Languages in Multilingual Dense RetrievalNandan Thakur , Jianmo Ni, Gustavo Hernández Ábrego, John Wieting, Jimmy Lin, Daniel CerTo appear in the 2024 Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL-HLT 2024)., 2024. University of Waterloo, Google Research and Google DeepMind. A large-scale synthetic LLM-generated dataset for improving multilingual retrieval systems without human-labeled training data. |
|
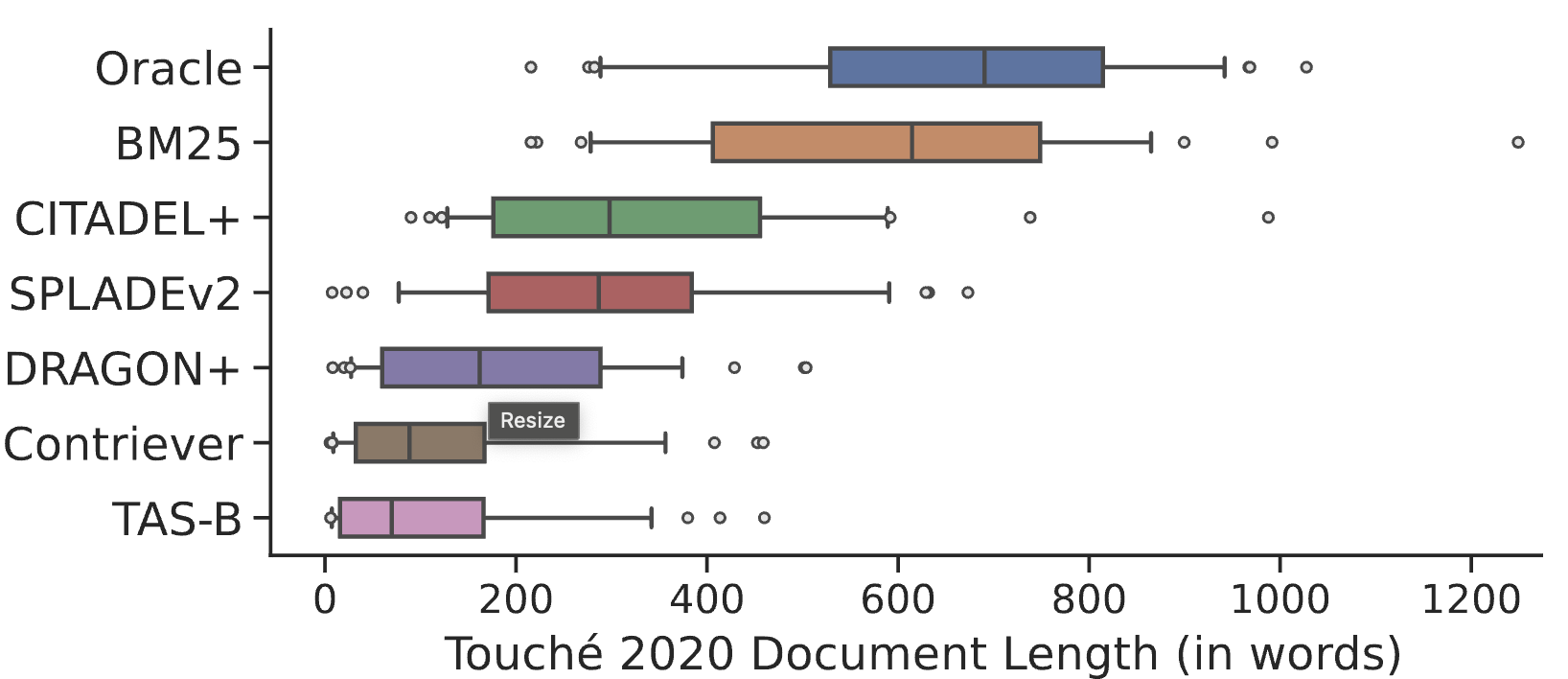
Systematic Evaluation of Neural Retrieval Models on the Touché 2020 Argument Retrieval Subset of BEIRNandan Thakur , Luiz Bonifacio, Maik Fröbe, Alexander Bondarenko, Ehsan Kamalloo, Martin Potthast, Matthias Hagen, Jimmy LinTo appear in SIGIR 2024 (Resource Track), 2024. University of Waterloo, UNICAMP, Univesity of Jena We denoise and conduct post-hoc judgments on the Touché 2020 Argument Retrieval Subset of BEIR. |
|
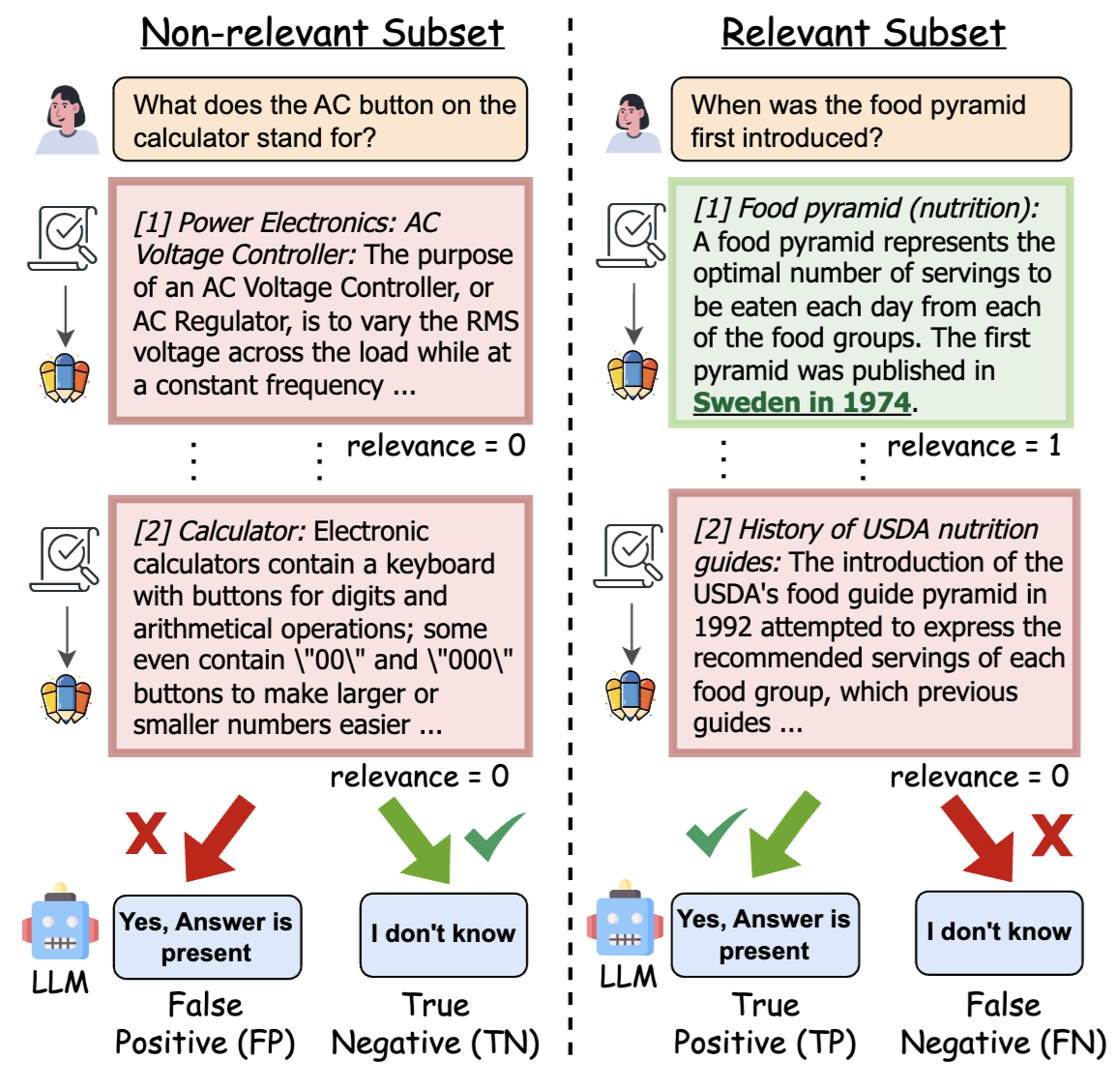
NoMIRACL: Knowing When You Don't Know for Robust Multilingual Retrieval-Augmented GenerationNandan Thakur , Luiz Bonifacio, Xinyu Zhang, Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Boxing Chen, Mehdi Rezagholizadeh, Jimmy LinArxiv Preprint, 2024. University of Waterloo, Huawei Noah’s Ark Lab A multilingual hallucination evaluation dataset for measuring LLM performance on non-answerable questions in RAG systems. |
2023
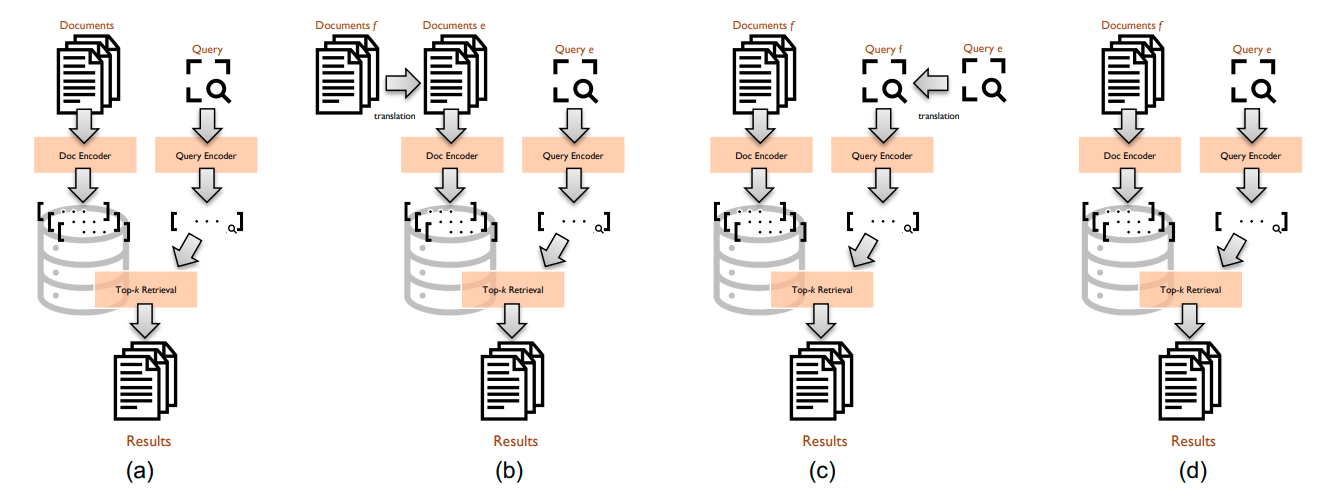
|
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information RetrievalJimmy Lin, David Alfonso-Hermelo, Vitor Jeronymo, Ehsan Kamalloo, Carlos Lassance, Rodrigo Nogueira, Odunayo Ogundepo, Mehdi Rezagholizadeh, Nandan Thakur , Jheng-Hong Yang, Xinyu Zhang.Arxiv Preprint, 2023. University of Waterloo, Huawei Noah’s Ark Lab, UNICAMP and Naver Labs Europe. Simple yet Effective Cross-lingual Baselines involving both sparse and dense retrieval models using IR Toolkits for test collections in the TREC 2022 NeuCLIR Track. |
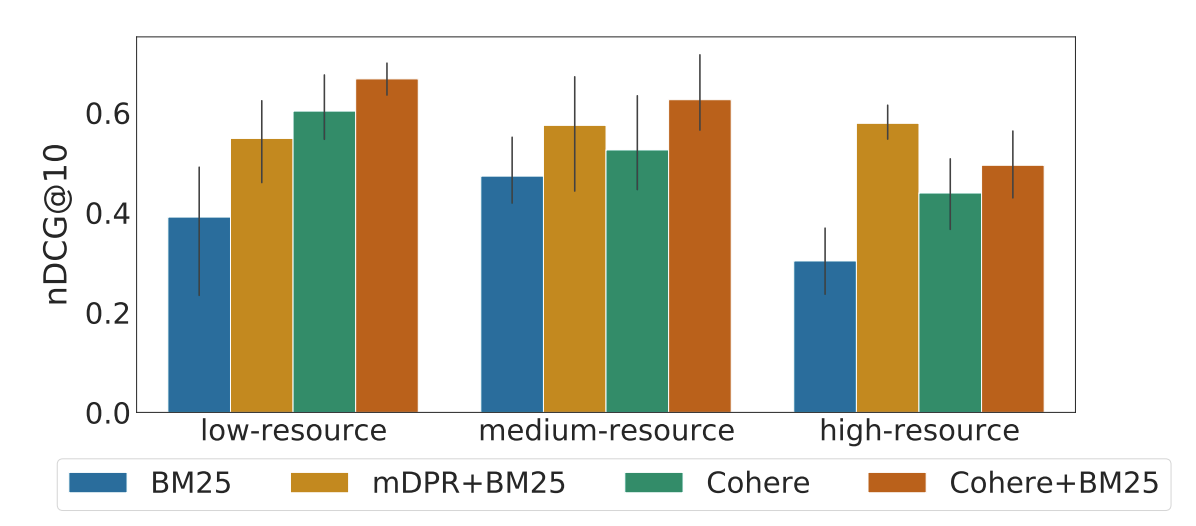
|
Evaluating Embedding APIs for Information RetrievalEhsan Kamalloo, Xinyu Zhang, Odunayo Ogundepo, Nandan Thakur , David Alfonso-Hermelo, Mehdi Rezagholizadeh, Jimmy Lin.Association for Computational Linguistics (ACL) 2023 Industry Track, 2023. University of Waterloo and Huawei Noah’s Ark Lab Analyze semantic embedding APIs in realistic retrieval scenarios in order to assist practitioners and researchers in finding suitable services. |
| |
SPRINT: A Unified Toolkit for Evaluating and Demystifying Zero-shot Neural Sparse RetrievalNandan Thakur , Kexin Wang, Iryna Gurevych, Jimmy Lin.In Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR ’23), 2023. University of Waterloo and UKPLab, Technical University of Darmstadt. A unified toolkit for evaluation of diverse zero-shot neural sparse retrieval models. |
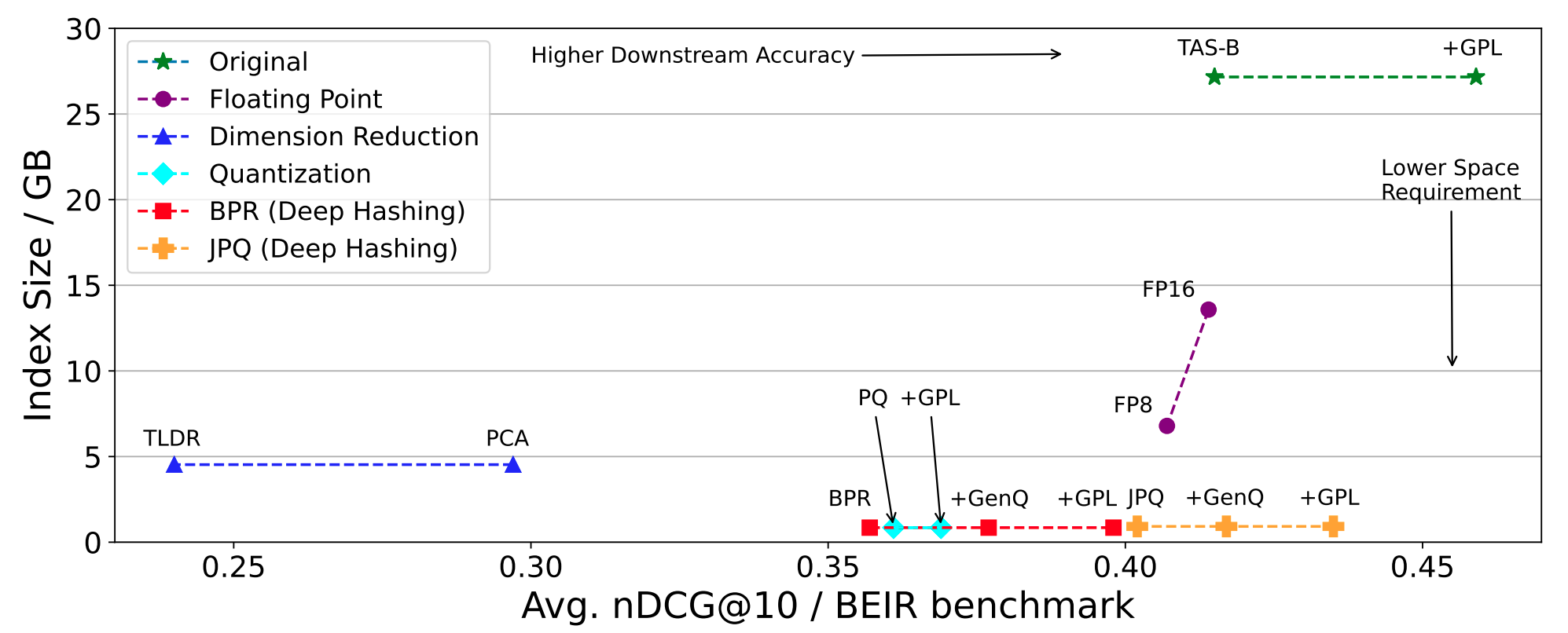
|
Injecting Domain Adaptation with Learning-to-hash for Effective and Efficient Zero-shot Dense RetrievalNandan Thakur , Nils Reimers, Jimmy Lin.2023 Workshop on Reaching Efficiency in Neural Information Retrieval (ReNeuIR’23), 2023. University of Waterloo, Cohere.ai A domain adaptation technique which is able to improve zero-shot performance of dense-retrieval models by maintaining 32x memory efficiency and latency. |

|
HAGRID: A Human-LLM Collaborative Dataset for Generative Information-Seeking with AttributionEhsan Kamalloo, Aref Jafari, Xinyu Zhang, Nandan Thakur , Jimmy Lin.Arxiv Preprint, 2023. University of Waterloo A high-quality dataset for training and evaluating generative search (RAG) models with citations. |
2022
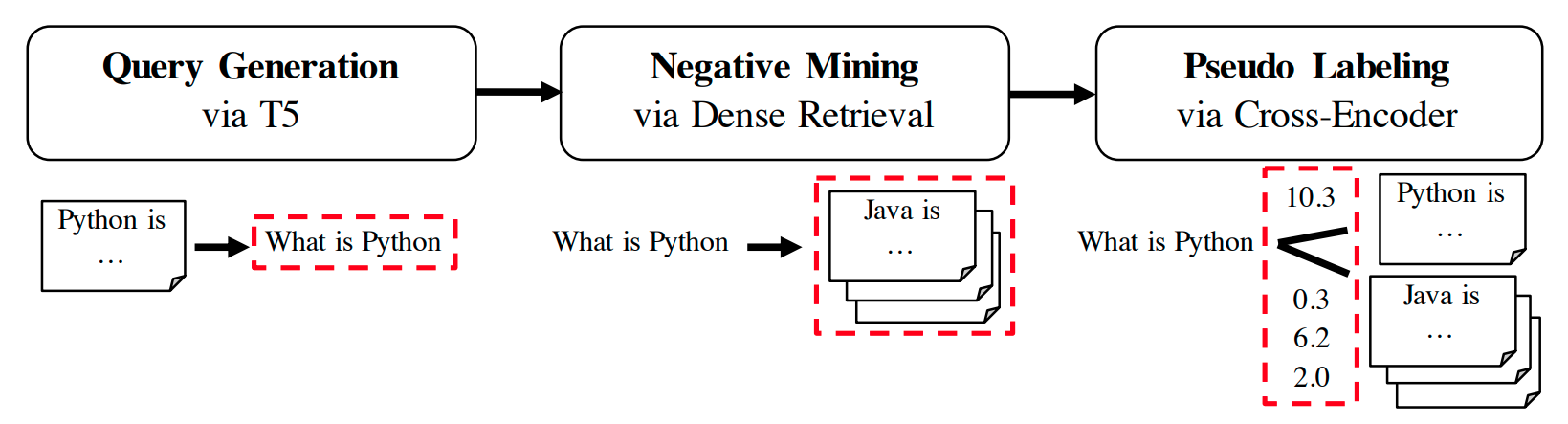
|
GPL: Generative pseudo labeling for unsupervised domain adaptation of dense retrievalKexin Wang, Nandan Thakur , Nils Reimers, Iryna Gurevych.Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2022. UKPLab, Technical University of Darmstadt A novel unsupervised domain adaptation method which combines a query generator with pseudo labeling from a cross-encoder. |

|
Making a MIRACL: Multilingual Information Retrieval Across a Continuum of LanguagesXinyu Zhang*, Nandan Thakur* , Odunayo Ogundepo, Ehsan Kamalloo, David Alfonso-Hermelo, Xiaoguang Li, Qun Liu, Mehdi Rezagholizadeh, Jimmy Lin.Proceedings of Transactions of the Association for Computational Linguistics (TACL), 2022. University of Waterloo and Huawei Noah’s Ark Lab A human-labeled multilingual retrieval dataset across 18 languages from diverse langauge families to progress retrieval systems across various languages. |
2021
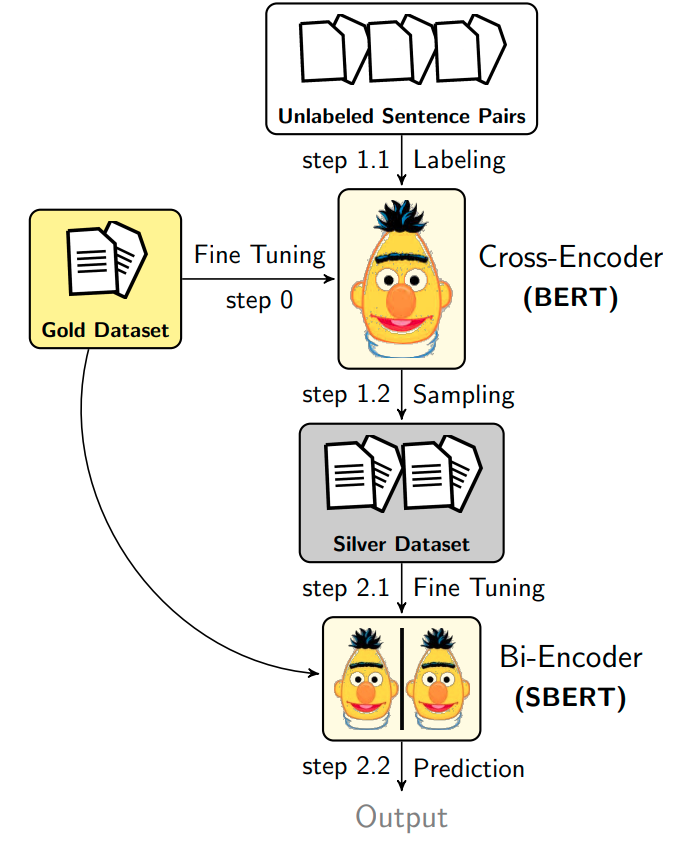
|
Augmented SBERT: Data Augmentation Method for Improving Bi-Encoders for Pairwise Sentence Scoring TasksNandan Thakur , Nils Reimers, Johannes Daxenberger, Iryna Gurevych.Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), 2021. UKPLab, Technical University of Darmstadt A simple yet efficient data augmentation strategy using the cross-encoder to label training data for training the bi-encoder for pairwise sentence scoring tasks. |
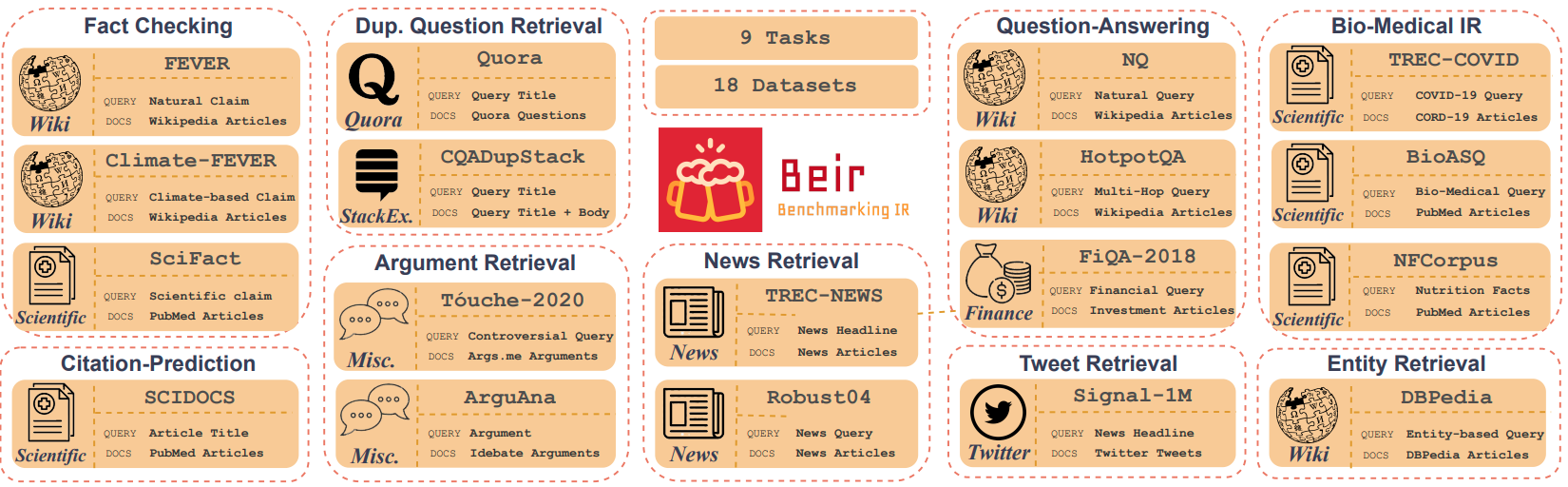
|
BEIR: A Heterogenous Benchmark for Zero-shot Evaluation of Information Retrieval ModelsNandan Thakur , Nils Reimers, Andreas Rücklé, Abhishek Srivastava, Iryna Gurevych.Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021. UKPLab, Technical University of Darmstadt A novel heterogeneous zero-shot retrieval benchmark containing 18 datasets from diverse text retrieval tasks and domains in English. |